The Magnus Prediction Model, version 5
Estimating Individual Impact on Penalty Rates
August 28, 2021, Micah Blake McCurdy, @IneffectiveMath
(This model, is the penalty version of Magnus 5. This explanation here is copied from there, with changes as appropriate.)
Introduction
I would like to be able to isolate the individual impact of a given skater on the penalties their team draws and takes. I take the philosophy that all of the skaters on the ice are jointly "responsible" for all non-offsetting minor penalties drawn and taken, without concentrating responsibility on the person who goes to the box and feels shame.
Method
I use a simple linear model of the form \( Y \sim WX\beta \) where \(X\) is the design matrix, \(Y\) is a vector of observations, \(W\) is a weighting matrix, and \(\beta\) is a vector of marginals, that is, the impacts associated to each thing, independent of each other things. Each passage of 5v5 play with no substitutions is encoded in the model as two rows; for the first row the response entry in \(Y\) is the rate of non-offsetting minor penalties drawn by the home team, for the second row it is the rate of non-offsetting minor penalties drawn by the road team.
Covariates
The columns of \(X\) correspond to all of the different features that I include in the model. There are broadly, two different types of columns. Some terms occur in pairs, one for offence, one for defence:
- Player performance estimates, two columns for each skater: one for their impact on drawing penalties and one for their impact on taking penalties.
The remaining terms apply only to the penalty-taking team:
- Score impacts: seven columns for various different scores:
- trailing by three or more,
- trailing by two,
- trailing by one,
- tied,
- leading by one,
- leading by two, and
- leading by three or more.
- Zone impacts: four columns for the zones in which penalty-taking
players start
their shifts. The four "shift start types" that I use are:
- Offensive Zone,
- Neutral Zone,
- Defensive Zone, and
- On the fly.
- Game Time and Venue: six columns indicating if the penalty-taking players are the
home or the road team and which period the stint is in:
- Home Team 1st Period,
- Home Team 2nd Period,
- Home Team 3rd Period,
- Away Team 1st Period,
- Away Team 2nd Period,
- Away Team 3rd Period,
- Two indicators, one called "repeat" for when the penalty-taking team is the team who took the most recent non-offsetting minor penalty; another called "switch" when the penalty-taking team is the other team. At the beginning of games, before either team has taken a penalty, these indicators are both set to zero.
Fitting
To fit a simple model such as \(Y = WX\beta \) using ordinary least squares fitting is to find the \(\beta\) which minimizes the total error $$ (Y - X\beta)^TW(Y - X\beta) $$ Since \(X\beta\) is the vector of model-predicted results (where \(\beta\) "is" the model), the difference between it and the observed results \(Y\) is a measure of error; forming the weighted product of \(Y-X\beta\) with itself is squaring this error (to ensure it's positive), and then we want to minimize this total error: hence the name "least squares".
However, I choose not to fit this model with ordinary least-squares, preferring instead to use generalized ridge regression; that is, instead of minimizing $$ (Y - X\beta)^TW(Y - X\beta) $$ as in ordinary least squares, I add three so-called ridge penalties, to instead minimize: $$ (Y - X\beta)^TW(Y - X\beta) \\ + (\beta-\beta_\Lambda)^T \Lambda (\beta - \beta_\Lambda) \\ + (\beta-\beta_K)^T K (\beta-\beta_K) \\ + \beta^T R \beta $$ Each ridge penalty has the same structure; the first term says that deviation of the model (that is, \(\beta\)) from the data is bad; the second term says that deviation of the model from the specified vector \(\beta_\Lambda\) is bad, and the matrix \(\Lambda\) controls how "bad" such deviation is to be considered. The four matrixes we use here (\(\Lambda\), \(K\), \(J\), and \(R\) with their attendant constant vectors \(\beta_\Lambda\), \(\beta_K\), \(\beta_J\), and zero, are how we specify our prior beliefs about the things being modelled, after we know what it is we are doing but before we consider the data itself.
The historical penalty
Although the exposition here focusses on 2020-2021, the most-recent season of NHL hockey as I write this, in practice I fit this model successively, first on 2007-2008, the first season for which the NHL provides data at this level of detail, and then repeating the process for all subsequent seasons. Thus, after each season, I have a suite of estimates of player ability which I do not throw away. Since I am trying to estimate player ability (not performance), I take the opinion that our estimates ought to change slowly, since a player's athletic ability also usually changes slowly. Furthermore, the game of hockey itself also changes (that is, its rules change, and also teams in the aggregate choose their players and playstyles differently) but does so slowly. Thus, every term in the model is biased towards its value from the previous season. This is done by taking \(\beta_\Lambda\) to be the \(\beta\) from the previous season, and populating the diagonal elements of \(\Lambda\) itself with the estimated precisions from the previous season. In 2007-2008, with no prior year of data to guide me, I use the zero vector instead, with a suitably broad uncertainty.
The regularization penalties
The normal penalty
The next two penalty terms encode our prior knowledge about the NHL specifically, about the overall quality of the players and coaches in it. In addition to returning players individually, we know that players who play in the league are selected; they have been drafted or signed from other leagues; every one of them has a substantial body of work examined by their managers and coaches, in one way or another. Furthermore, the athletic abilities themselves which we are primarily interested in are constrained, very generally, by what we know about the possibilities of human performance, and ultimately by physics itself. In particular, this means that extreme estimates are unlikely for this reason, regardless of the happenstances of any on-ice observations. Thus, we impose a penalty on every skater towards "NHL average". This is the "usual" ridge penalty, \( (\beta-\beta_K)^T K (\beta-\beta_K)\), where \(\beta_K\) is conveniently the zero vector, since "league average" each season is the reference point we choose to use for our regression.
A truly disciplined modeller would have used the league average from the previous year, in order to maintain faithful observance of using only prior data in specifying the prior, but I have cheated slightly and used the data from the season at hand instead. I crave the reader's forgiveness.
The strength of the penalty is encoded into the diagonal entries of \(K\) as follows:- For the score columns, the zone columns, and the home/road period columns, I choose a penalty of 0. These terms are not theoretically constrained, and the fitting in this region of the model is like ordinary-least-squares fitting.
- For coaching and player terms, I use a value in \(K\) of 50,000. Choosing this value is somewhat ad hoc; but does produce stable, slowly varying estimates. More involved theoretical estimates of optimal penalty values (such as computing the generalized cross-validation error, following Brian MacDonald (Section 5.3)) suggest much smaller values which give wildly varying (and hence unworkable) year-to-year estimates of player ability.
Players that we expect before we see their on-ice results or circumstances to be of similar ability can be fused, that is, penalty terms can be introduced to encode our prior belief that they are similar. I have chosen to fuse the Sedins in this way, with a penalty term of weight 50,000, because they are twins. I don't consider any more-distant relation than twins as legitimate grounds for this kind of prior.
Pooling penalties
Finally, I apply a set of penalties to encode prior knowledge about how the various structural terms are distributed, so that certain sets of terms can be "pooled" properly. For example; whatever the particulars of who starts which shifts in which zones, we expect that the total impact of zone starts on the entire league over a season to be zero, since every effect that helps one team should have a matching effect hurting their opponents. In previous iterations of this model I have worked around this by using one shift-start state (on-the-fly) as the "reference" state, thus having no model term, and then using indicators variables for the others (neutral zone, defensive zone, and offensive zone). However, this is a shade clumsy, requiring us to understand every term as "change from an on-the-fly shift", rather than, as I would strongly prefer, as "change from average".
Generally, if there are terms \(a_k\) in a model and we have weights \(w_k\) and would like to enforce $$ \sum_{k} w_ka_k = 0 $$ it suffices to ask that the square of \((\sum w_ka_k)^2\) should be small; expanding the square and interpeting the coefficients of each \(a_ia_j\) as the element \(R_{ij}\) of the penalty matrix \(R\) does the trick.
So, after forming the design matrix \(X\), but before considering the on-ice results \(Y\), we can obtain the relevant weights \(w_k\) with which to encode our prior expectation that shift-start terms should be, in aggregate, zero-sum.
For instance, if \(i\) is the index for the neutral zone term, and 17.5% of shifts in a given season begin in the neutral zone; and \(j\) is the index for on-the-fly starts, and 60.5% of shifts in a given season begin on-the-fly; then \(R_{ij}\) is set to the product of 17.5% with 60.5%; similarly with every ordered pair of zone terms to give sixteen non-zero entries in \(R\).
In the same way, we enforce that:
- The seven score terms should (weighted) sum to zero;
- The four zone terms should sum to zero;
- The six "structure" (period and home/away) terms should sum to zero;
All of these pooling penalties are multiplied by an extremely strong factor (a million times larger than the 50,000 penalty for the players above). Deviation from average for players is increasingly unlikely (but not impossible) as the deviation grows; here deviations from the desired sums are contradictions in terms.
The model can be fit to any length of time; in this article I'll be describing the results of fitting it iteratively on each season from 2007-2008 through 2020-2021 in turn. For 2007-2008, we use "NHL average"; for later seasons I use the estimate from the previous season as the prior for each column, when present.
Computational Details
So, after all that, the thing we would like to put our impatient hands on is the vector \(\beta\) which minimizes the following expression: $$ (Y - X\beta)^TW(Y - X\beta) + (\beta-\beta_\Lambda)^T \Lambda (\beta - \beta_\Lambda) + (\beta-\beta_K)^T K (\beta-\beta_K) + \beta^T R \beta $$
Happily, the usual methods (that is, differentiating with respect to \(\beta\) to find the unique minimum of the error expression) gives a closed form for \(\beta\) as: $$ \beta = (X^TWX + \Lambda + K + R)^{-1}(X^TW Y + \Lambda \beta_\Lambda + K\beta_K ) $$ In effect, instead of assuming every season that the league is full of new players about whom we know nothing, we use all of the information from the last dozen years, implicitly weighted as seasons pass to prefer newer information without ever discarding old information entirely.
Persnickety folks, who might wonder if there really is a unique minimum to the complicated error expression we wish to minimize, may rest assured that it suffices for all of the penalty matrixes \(\Lambda\), \(K\), and \(R\) to all be positive semi-definite, which they are, as motivated readers may verify at their leisure. (For the etymologically and historically curious, ridge regression was invented in the first place by folks who were interested in solving problems where the matrix \(X^TWX\) was not invertible because a certain subspace of the columns of \(X\) was "too flat" in some quasi-technical sense. The artificial inserted matrix \(\Lambda\) adds a "ridge" in this notional geometry and makes the sum \(X^TWX + \Lambda\) conveniently invertible. The Bayesian "prior" interpretation, so important to my approach here, was discovered somewhat later.)
Results
Throughout the results here, positive values mean "more likely to take a penalty" (than average) and negative values mean "less likely to take a penalty".
Game State
First, we consider the effect of being the home team vs being the road team, through each period.
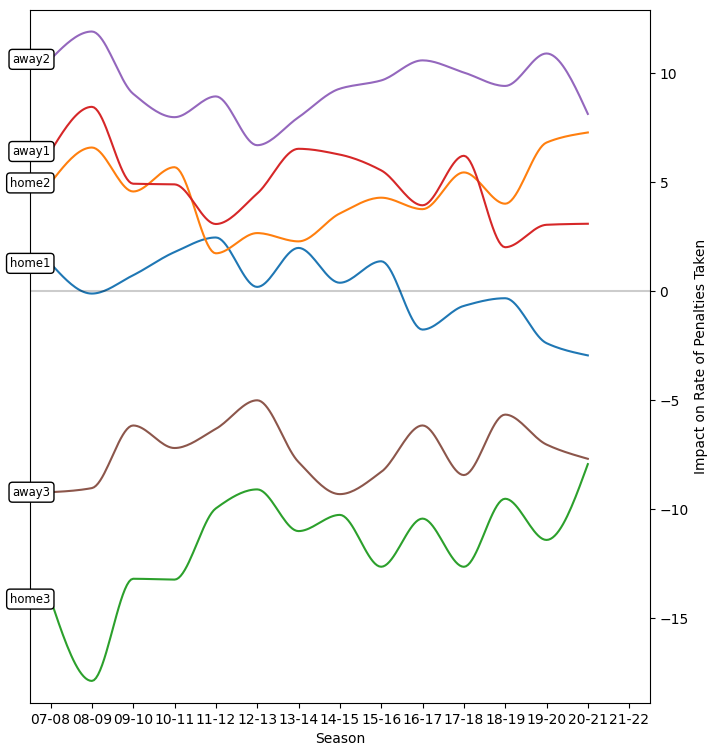
Unsurprisingly, the road team is more likely take penalties than the home team in every period; but both teams commit infractions considerably less in the third period. To a smaller extent, the second period is more penalty-filled than average.
Score
We know that the score affects how teams generate and suppress shots; it also has an effect on penalty rates.
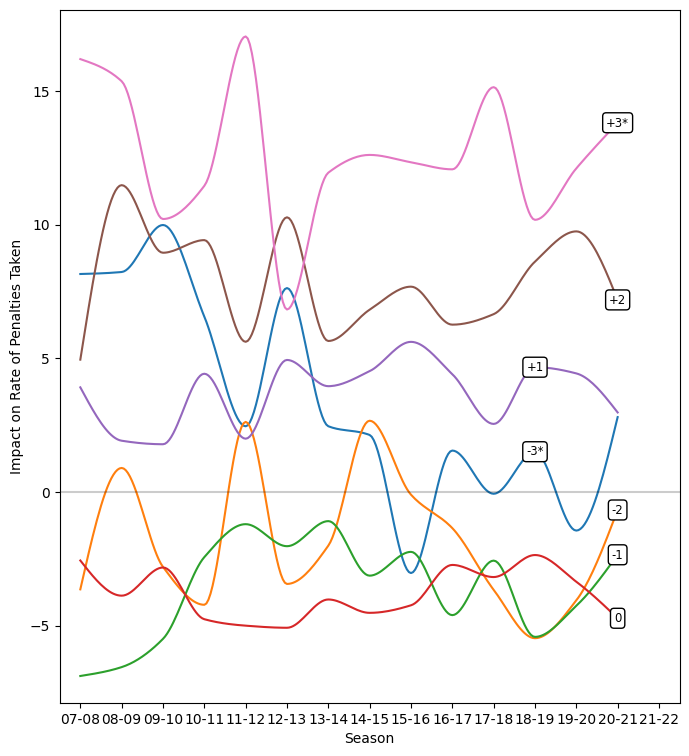
The strongest effect on penalties is that leading teams take them more often; the larger the lead, the larger the effect. To a much smaller extent, trailing teams take fewer penalties, with tied teams taking the fewest. Tie games are more conservative in shot rates also; I suspect the effect on shots and penalties arises from a similar caution when tied.
Zone
The zone in which shifts are started also affects penalty rates:
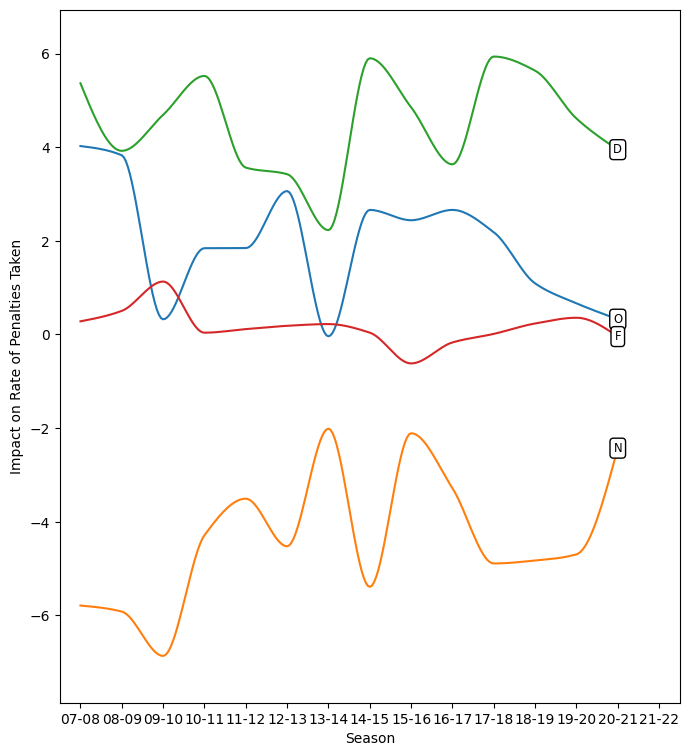
On-the-fly shifts unsurprisingly are associated with minimal change in penalty rates, as one might expect since most shifts are started on-the-fly and such shift starts occur all over the ice. Also as expected is the rise in penalties taken by teams whose players start in their own zone. Somewhat more interesting is the small rise in penalties taken by players starting the offensive zone. Neutral zone starts are associated with drops in penalty rates but the effect is smaller now than it once was.
Switch and Repeat
One of the most interesting things about penalties is that they show a strong relationship among themselves within a game. The most obvious form of this is the so-called "make-up" call, where a team that commits a penalty (especially a marginal one that might just as well gone un-called, anecdotally) is frequently followed shortly by a penalty call against the other team.
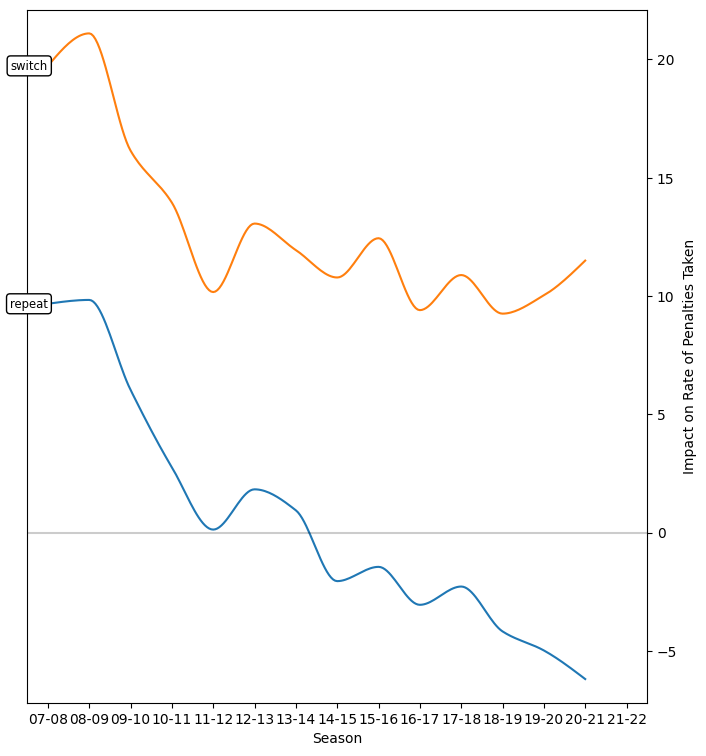
Both "switch" and "repeat" terms show a marked decline over the last fourteen years; surprisingly the difference between them (the tendency to call the "other" team for the next penalty rather than the same team again) has remained roughly constant over that whole team. This effect is the subject of a great deal of (largely deserved) complaint about the league, especially in the playoffs where it is seemingly more salient (this work is confined to the regular season, however). It is commonplace to see the effect blamed on referees, imagined (perhaps correctly) to scrutinize the "other" team more carefully than the "same" team who was recently penalized, perhaps even to the point of turning a blind eye to repeat offences. It is also possible that this effect is partially attributable to players for the recently-penalized team responding to that penalty by playing more cautiously, committing fewer "borderline" infractions. A subtle analysis that could capture one or both effects seems beyond me at this moment.
Previous Work and Acknowledgements
Using zero-biased (also known as "regularized") regression in sports has a long history; the first application to hockey that I know of is the work of Brian MacDonald in 2012. His paper notes many earlier applications in basketball, for those who are curious about history; also I am very grateful for many useful conversations with Brian during the preparation of the first version of Magnus. Shortly after MacDonald's article followed a somewhat more ambitious effort from Michael Schuckers and James Curro, using a similar approach. Persons interested in the older history of such models will be delighted to read the extensive references in both of those papers.
More recently, regularized regression has been the foundation of WAR stats from both Emmanuel Perry and Josh and Luke Younggren, who publish their results at Corsica (now sadly defunct) and Evolving-Hockey, respectively.
Finally, I am very thankful to Luke Peristy for many helpful discussions, and to the generalized ridge regression lecture notes of Wessel N. van Wieringen which were both of immense value to me.