The Magnus Prediction Model, version 4
Estimating Individual Impact on NHL 5v5 Shot Rates
November 23, 2020, Micah Blake McCurdy, @IneffectiveMath
(This model, "Magnus 4", is an updated version of Magnus 3, released earlier this year. In the interests of providing a self-contained documentation here, I've copied the explanation there with changes as appropriate.)
What's New
For old hands who want to know the quick rundown of what is new this version:- I've added explicit "turtle" terms, attached to coaches defending ties or small leads in the third period.
- I've included on-the-fly starts explicitly instead of using them as a reference state, making the zone distributions easier to understand.
- I've included "tied" explicitly instead of using it as a reference state, making the score distributions easier to understand.
- I've reworked the "state state" terms to use six terms (home or away, for each period) instead of the single "home" and "long-change" terms as previously.
Introduction
I would like to be able to isolate the individual impact of a given skater on shot rates from the impact of their teammates, their opponents, the scores at which they play, the zones in which they begin their shifts, the instructions of their head coach, their level of fatigue, how far away their bench is, and home-ice advantage. I have fit a regression model which provides such estimates. The most important feature of this model is that I use shot rate maps as the units of observation and thus also for the estimates themselves, permitting me to see not only what portion of a team's performance can be attributed to individual players but also detect patterns of ice usage.
Here, as throughout this article, "shot" means "unblocked shot", that is, a shot that is recorded by the NHL as either a goal, a save, or a miss (this latter category includes shots that hit the post or crossbar). I would prefer to include blocked shots also but cannot since the NHL does not record shot locations for blocked shots.
The most sophisticated element of Magnus is the method for estimating the marginal effect of a given player on shot rates; that is, that portion of what happens when they are on the ice that can be attributed to their individual play and not the context in which they are placed. We know that players are affected by their teammates, by their opponents, by the zones their coaches deploy them in, and by the prevailing score while they play. Thus, I try to isolate the impact of a given player on the shots which are taken and where they are taken from.
Although regression is more mathematically sophisticated than some other measures, it is in no way a "black box". As we shall see, every estimate can be broken down into its constituent pieces and scrutinized. If you are uneasy with the mathematical details but interested in the results, you should skip the "Method" section and just think of the method as like a souped-up "relative to team/teammate statistics", done properly.
Method
I use a simple linear model of the form \( Y \sim WX\beta \) where \(X\) is the design matrix, \(Y\) is a vector of observations, \(W\) is a weighting matrix, and \(\beta\) is a vector of marginals, that is, the impacts associated to each thing, independent of each other things. Each passage of 5v5 play with no substitutions is encoded in the model as two rows, one row with the home team as the attacking team, where the response entry in \(Y\) is the pattern of shots taken by the home team, and another row with the road team as the attacking team, where the response entry in \(Y\) is their pattern of shots. I call such passages of play with no substitutions "stints", by analogy with the same term used in basketball research, although the presence of on-the-fly changes in hockey mean that some stints can be very short. Note also that a single stint can contain within it several stoppages of play, including a variety of faceoffs, so long as the players on the ice do not change. A typical NHL season contains about a quarter million stints and so our design matrix \(X\) has about half a million rows. Happily, as we shall see momentarily, there are only about two thousand covariates, so \(X\) has about a billion entries, most of which are zero. This is computationally non-trivial but still tractable with a level head and some half-decent computers.
Covariates
The columns of \(X\) correspond to all of the different features that I include in the model. There are broadly, two different types of columns. Some terms occur in pairs, one for offence, one for defence:
- Player performance estimates, two columns for each skater: one for their offensive impact (that is, on their own team's shot rates), and one for their defensive impact (that is, on their opponent's shot rates);
- Coach impacts: two pairs columns for the head coach of each team,
- one pair for general impact (attacking/defending), meant to serve as an umbrella for the effect the coach's instructions have on how the players on the ice choose to play;
- another pair of attacking/defending "shell" indicators used only in "turtling" positions, that is, when tied or leading by one or two in third periods; these times are chosen because score effects are driven primarily by leading teams.
- Rest impacts: eight columns for "played last night", "played two nights ago", "played three nights ago", and "played four nights ago", separated into offence and defence for each.
The remaining terms apply only to the offensive team:
- Score impacts: seven columns for various different scores:
- trailing by three or more,
- trailing by two,
- trailing by one,
- tied,
- leading by one,
- leading by two, and
- leading by three or more.
- Zone impacts: four columns for the zones in which attacking players start
their shifts. The four "shift start types" that I use are:
- Offensive Zone,
- Neutral Zone,
- Defensive Zone, and
- On the fly.
- Game Time and Venue: six columns indicating if the attacking players are the
home or the road team and which period the stint is in:
- Home Team 1st Period,
- Home Team 2nd Period,
- Home Team 3rd Period,
- Away Team 1st Period,
- Away Team 2nd Period,
- Away Team 3rd Period,
Response
The entries in \(Y\), the "responses" of the regression, are functions which encode the rate at which unblocked shots are generated from various parts of the ice. An unblocked shots with NHL-recorded location of \((x,y)\) is encoded as a two-dimensional gaussian centred at that point with width (standard deviation) of ten feet; this arbitrary figure is chosen because it is large enough to dominate the measurement error typically observed by comparing video observations with NHL-recorded locations and also produces suitable smooth estimates.
One detailed example (with no-longer current players for either team, but no matter) should make the structure of the model clear:
Suppose that the Senators are the home team and the Jets are the away team, and at a given moment of open play two Senators players (say, Karlsson and Phaneuf) jump on the ice, replacing two other Senators. This begins a new "stint". The score is 2-1 for Ottawa in the third period, and the other players (say, Pageau, Hoffman, and Stone for Ottawa, against Laine, Ehlers, Wheeler, Byfuglien, and Enstrom) began their shift some time previously on a faceoff in Ottawa's zone. Play continues for 50 seconds, during which time Ottawa takes two unblocked shots from locations (0,80) and (-10,50) and Winnipeg takes no shots. This shift ends with the period and the players leave the ice. The game is the season-opener for Winnipeg, but Ottawa played their first game yesterday, using all of the named players except Phaneuf, who was scratched in that game for unspecified reasons, causing a great deal of unproductive twittering.
These fifty seconds are turned into two rows of \(X\) and two entries in \(Y\). First, the Ottawa players are considered the attackers, and the attacking columns for Pageau, Hoffman, Stone, Karlsson, and Phaneuf are all marked as "1". The Jets are considered the defenders and the defending columns for Laine, Ehlers, Wheeler, Byfuglien, and Enstrom are marked as "1". All of the other player columns, attacking or defending, are marked as "0". Because the Senators are winning 2-1, the score column for "leading by one" is marked with a "1" and the other score columns are marked as "0". Three of the Senators players are playing on-the-fly shifts, while the other two Senators skaters (that is, 40% of the skaters) are still playing the shift they began in their own zone, so the "home defensive-zone attacking" zone column is marked with "0.4" and the "home on-the-fly attacking" zone column is marked with "0.6". The zones that the Jets players began /their/ shifts in are not considered at this time. The Senators are the home team, so the "home 3rd" column is marked with a 1. The column for "Guy Boucher, attacking coach" is marked with a one, while the column for "Paul Maurice, defending coach" is marked with a one. Additionally, since Ottawa is leading by one in the third period, the "Guy Boucher, shell offence" term is marked with a one, all the other coaching columns are marked with zeros. Since all of Winnipeg players are well-rested, no rest columns are marked for defence. Phaneuf is well-rested for Ottawa, but the other four skaters played last night, so the column for "played last night, attackers", is marked with 0.8, since 80% of the attacking skaters did so. All the other other rest columns are marked with zeros. Corresponding to this row of \(X\), an entry of \(Y\) is constructed as follows: Two gaussians of ten-foot width and unit volume are placed at (0,80) and (-10,50) and the two gaussians are added to one another. This function is divided by fifty (since the stint is fifty seconds long); resulting in a continuous function that approximates the observed shot rates in the shift. Finally, I subtract the league average shot rate from this. This function, which associates to every point in the offensive half-rink a rate of shots produced in excess of league average from that location, is the "observation" I use in my model.Second, the same fifty seconds are made into another observation where the Jets players are considered the attackers, and the Senators are the defenders. The attacking player columns for the Jets are set to 1, the defending columns for the Senators players are set to 1. Since the Jets are losing, the score column of "trailing by one" is set to one. Since all of the Jets skaters are in the middle of an offensive-zone shift, the "OZ" term is marked as 1; the Senators shift start locations are not considered here. The columns for "Guy Boucher, defending coach", and "Guy Boucher, shell defence", and "Paul Maurice, attacking coach" are each marked with a one, and all the other coaching columns are marked with zeros. Since all of Winnipeg players are well-rested, no rest columns are marked for offence. Phaneuf is well-rested for Ottawa, but the other four skaters played last night, so the column for "played last night, defenders", is marked with 0.8, since 80% of the defending skaters did so. All the other other rest columns are marked with zeros. The two rows have no non-zero columns in common. Since the Jets didn't generate any shots, the associated function is the zero function; I subtract league average shot rate from this and the result is placed in the observation vector \(Y\).
The weighting matrix \(W\), which is diagonal, is filled with the length of the shift in question. Thus, the above two rows will each have a weight of fifty.
By controlling for score, zone, teammates, and opponents in this way, I obtain estimates of each players individual isolated impact on shot generation and shot suppression.
Fitting
To fit a simple model such as \(Y = WX\beta \) using ordinary least squares fitting is to find the \(\beta\) which minimizes the total error $$ (Y - X\beta)^TW(Y - X\beta) $$ Since \(X\beta\) is the vector of model-predicted results (where \(\beta\) "is" the model), the difference between it and the observed results \(Y\) is a measure of error; forming the weighted product of \(Y-X\beta\) with itself is squaring this error (to ensure it's positive), and then we want to minimize this total error: hence the name "least squares".
When the entries of \(Y\) are numbers, this error expression is a one-by-one matrix which I naturally identify with the single number it contains, and I can find the \(\beta\) which minimizes it by the usual methods of matrix differentiation. To extend this framework to our situation, where the elements of \(Y\) are shot maps, I use a dissection of the half-rink into ten-thousand pieces, as a hundred-by-hundred grid. This divides the rink up into parcels one foot long by 0.85 feet wide, sufficiently coarse to permit efficient computation and sufficiently fine to appear smooth when results are gathered together. In particular, since the input shot data is smoothed into sums of gaussians before the regression is fit, we can compute the regression as if it were ten thousand separate regressions whose outputs are combined to form the maps for each term. It might be helpful to imagine a video broadcasting system, where input video is spliced into channels, each channel modified by appropriate filters for the display media at hand, and then each channel organized into an output which viewers can percieve as a single object. The practical benefit of this is that I can use the well-known formula for the \(\beta\) which minimizes this error, namely $$ \beta = (X^TX)^{-1}X^TWY $$ which makes it clear that the units of \(\beta\) are the same as those of \(Y\); that is, if I put shot rate maps in, I will get shot rate maps out.
However, I choose not to fit this model with ordinary least-squares, preferring instead to use generalized ridge regression; that is, instead of minimizing $$ (Y - X\beta)^TW(Y - X\beta) $$ as in ordinary least squares, I add three so-called ridge penalties, to instead minimize: $$ (Y - X\beta)^TW(Y - X\beta) \\ + (\beta-\beta_\Lambda)^T \Lambda (\beta - \beta_\Lambda) \\ + (\beta-\beta_K)^T K (\beta-\beta_K) \\ + (\beta-\beta_J)^T J (\beta-\beta_J) \\ + \beta^T R \beta $$ Each ridge penalty has the same structure; the first term says that deviation of the model (that is, \(\beta\)) from the data is bad; the second term says that deviation of the model from the specified vector \(\beta_\Lambda\) is bad, and the matrix \(\Lambda\) controls how "bad" such deviation is to be considered. The four matrixes we use here (\(\Lambda\), \(K\), \(J\), and \(R\) with their attendant constant vectors \(\beta_\Lambda\), \(\beta_K\), \(\beta_J\), and zero, are how we specify our prior beliefs about the things being modelled, after we know what it is we are doing but before we consider the data itself.
The historical penalty
Although the exposition here focusses on 2019-2020, the most-recent season of NHL hockey as I write this, in practice I fit this model successively, first on 2007-2008, the first season for which the NHL provides data at this level of detail, and then repeating the process for all subsequent seasons. Thus, after each season, I have a suite of estimates of player ability which I do not throw away. Since I am trying to estimate player ability (not performance), I take the opinion that our estimates ought to change slowly, since a player's athletic ability also usually changes slowly. Furthermore, the game of hockey itself also changes (that is, its rules change, and also teams in the aggregate draft and play differently) but does so slowly. Thus, every term in the model is biased towards its value from the previous season. This is done by taking \(\beta_\Lambda\) to be the \(\beta\) from the previous season, and populating the diagonal elements of \(\Lambda\) itself with the estimated precisions from the previous season. In 2007-2008, with no prior year of data to guide me, I use the zero vector instead.
The regularization penalties
The normal penalty
The next two penalty terms encode our prior knowledge about the NHL specifically, about the overall quality of the players and coaches in it. In addition to returning players individually, we know that players who play in the league are selected; they have been drafted or signed from other leagues; every one of them has a substantial body of work examined by their managers and coaches, in one way or another. Furthermore, the athletic abilities themselves which we are primarily interested in are constrained, very generally, by what we know about the possibilities of human performance, and ultimately by physics itself. In particular, this means that extreme estimates are unlikely for this reason, regardless of the happenstances of any on-ice observations. Thus, we impose a penalty on every skater towards "NHL average". This is the "usual" ridge penalty, \( (\beta-\beta_K)^T K (\beta-\beta_K)\), where \(\beta_K\) is conveniently the zero vector, since "league average" each season is the reference point we choose to use for our regression.
A truly disciplined modeller would have used the league average from the previous year, in order to maintain faithful observance of using only prior data in specifying the prior, but I have cheated slightly and used the data from the season at hand instead. I crave the reader's forgiveness.
The weird penalty
A "standard" ridge penalty, applied equally to all players of all abilities in the same direction (that is, towards zero), is consistent with an intuition that the distribution of talent in the league is roughly arranged as a normal distribution around its centre. However, as an "apex" league, which (mostly) gathers the best men's hockey players and (largely) does not relinquish them, we should expect the distribution of talent to be skewed towards better players. Specifically, we should expect the best players to be more better than the average players than the worst players are worse than average, since such low-performers can be replaced with plausibly-better players (even if these replacements have no NHL experience) but the high-performers have no reason to leave.
Therefore, as a crude way of making a prior which might result in such a right-skewed distribution of ability might result, I include a second, weaker penalty, not towards average but towards an ability slightly worse than average, both offensively and defensively. Specifically I choose a \(\beta_J\) to be the constant vector whose entries are -2% offensively, relative to league average, and +3% defensively, relative to league average. This is the "weird" ridge penalty, \( (\beta-\beta_J)^T J (\beta-\beta_J)\).
Although there are two penalties (one for J and one for K), you should think of them together as specifying, in a rough-and-ready sort of way, the kind of distribution of abilities we think is present in the league before try to estimate any particular individual's ability.
The relative strengths of the two penalties is encoded into the diagonal entries of \(K\) and \(J\) as follows:- For the score columns, the zone columns, the rest columns, the long change term, and the home-ice intercept, I choose a value of 0. These terms are not theoretically constrained, and the fitting in this region of the model is like ordinary-least-squares fitting.
- For all other terms (for players, zones, and scores) I use a value of 7,500 in K and 2,500 in J. The sum of the two terms is 10,000; which readers may remember from previous years, when I used it after examining the estimates for various penalty strengths and choosing a sufficiently high value for stable, slowly varying estimates. More involved theoretical estimates of optimal penalty values (such as computing the generalized cross-validation error, following Brian MacDonald (Section 5.3)) suggest much smaller values which give wildly varying year-to-year estimates of player ability.
- For coaching terms, I use a value in \(K\) of 37,500, that is, five times as biased towards NHL-average as for skaters; and a value in \(J\) of 2,500, matching the player bias. These ratios have no theoretical justification, and are motivated by my judgment that coaching influence, while diffuse and omni-present, is necessarily limited by the fact that they are not actually on the ice and can only influence results indirectly, through the imperfect conduits of their instructions, rewards, and punishments to skaters.
- Rookies or other players with low icetimes are not treated differently in any way, unlike in the first version of Magnus.
Players that we expect before we see their on-ice results or circumstances to be of similar ability can be fused, that is, penalty terms can be introduced to encode our prior belief that they are similar. I have chosen to fuse the Sedins in this way, with a penalty term of weight 10,000, because they are twins. I don't consider any more-distant relation than twins as legitimate grounds for this kind of prior.
Pooling penalties
Finally, I apply a set of penalties to encode prior knowledge about how the various structural terms are distributed, so that certain sets of terms can be "pooled" properly. For instance, the distribution of shift starts by zone is broadly constant across many years, with a long-term average of 11.7% of shifts starting in the offensive zone, 10.3% in the defensive zone, 17.5% in the neutral zone, and the remaining 60.5% on the fly. Thus, we expect that the four attacking terms in the model for these zones should sum to zero, when weighted with these percentages. This reflects our desire that our baseline for the whole regression should be "average" for all of hockey, that is, independent of zone. Happily for us, a weighted sum of terms being zero can be described using a positive semi-definite matrix, and so can be used as a penalty matrix in a ridge regression.
Specifically, if there are terms \(a_k\) in a model and we have weights \(w_k\) and would like to enforce $$ \sum_{k} w_ka_k = 0 $$ it suffices to ask that the square of \((\sum w_ka_k)^2\) should be small; expanding the square and interpeting the coefficients of each \(a_ia_j\) as the elements of the penalty matrix \(R\) does the trick. For instance, if \(i\) is the index for the neutral zone term, and \(j\) is the index for on-the-fly starts, then \(R_{ij}\) is set to the product of 17.5% with 60.5%; similarly with every ordered pair of zone terms to give sixteen non-zero entries in \(R\).
In the same way, we enforce that the score terms should pool suitably, again using the long-term average of the prevalence of each score state for the home team, that is:
- Down three or more: 4.42%
- Down two: 7.14%
- Down one: 17.03%
- Tied: 36.78%
- Up one: 19.25%
- Up two: 8.85%
- Up three or more: 6.56%
Similarly, we pool the offensive rest terms with one another and also the defensive ones, with historical weights:
- Played yesterday: 11.6%
- Played two days ago: 35.7%
- Played three days ago: 25.1%
- Played four days ago: 27.5%
And finally, we pool the six game state terms to sum to zero, with equal weights since they are all equally common.
All of these pooling penalties are extremely strong, in numerical terms a million times as strong as the previous penalties.
The model can be fit to any length of time; in this article I'll be describing the results of fitting it iteratively on each season from 2007-2008 through 2018-2019 in turn. For 2007-2008, we use "NHL average"; for later seasons I use the estimate from the previous season as the prior for each column, with NHL average for new players or coaches.
Computational Details
So, after all that, the thing we would like to put our impatient hands on is the vector \(\beta\) which minimizes the following expression: $$ (Y - X\beta)^TW(Y - X\beta) + (\beta-\beta_\Lambda)^T \Lambda (\beta - \beta_\Lambda) + (\beta-\beta_K)^T K (\beta-\beta_K) + (\beta-\beta_J)^T J (\beta-\beta_J) + \beta^T R \beta $$
Happily, the usual methods (that is, differentiating with respect to \(\beta\) to find the unique minimum of the error expression) gives a closed form for \(\beta\) as: $$ \beta = (X^TWX + \Lambda + K + J + R)^{-1}(X^TW Y + \Lambda \beta_\Lambda + K\beta_K + J\beta_J) $$ In effect, instead of assuming every season that the league is full of new players about whom we know nothing, we use all of the information from the last dozen years, implicitly weighted as seasons pass to prefer newer information without ever discarding old information entirely.
Persnickety folks, who might wonder if there really is a unique minimum to the complicated error expression we wish to minimize, may rest assured that it suffices for all of the penalty matrixes \(\Lambda\), \(K\), \(J\), and \(R\) to all be positive semi-definite, which they are. (For the etymologically and historically curious, ridge regression was invented in the first place by folks who were interested in solving problems where the matrix \(X^TWX\) was not invertible because a certain subspace of the columns of \(X\) was "too flat" in some quasi-technical sense. The artificial inserted matrix \(\Lambda\) adds a "ridge" in this notional geometry and makes the matrix conveniently invertible. The Bayesian "prior" interpretation, so important to my approach here, was discovered somewhat later.)
Results
Game State
Every column in the regression corresponds to a map of shot rates over a half-rink. The simplest are perhaps the six "game state" terms:
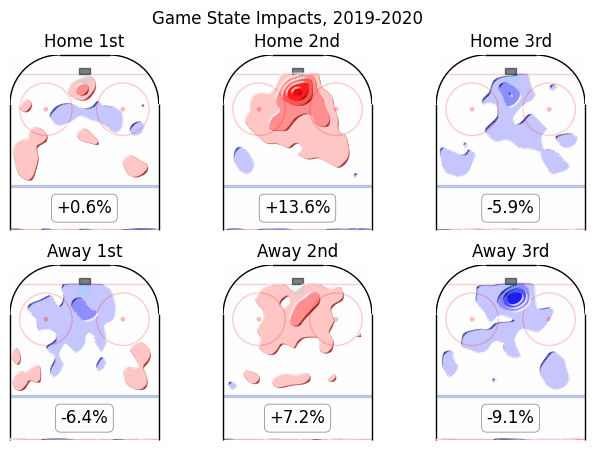
Unsurprisingly, the home team has an advantage in each period, while the second period shows an uptick in shot danger for both teams. Perhaps more surprisingly, the third period shows a decrease in shots for both teams relative to the first period, even after accounting for score effects.
All of the maps are depicted here are to be understood as relative to league average expected goals for the season in question. Regions in red show more-and-more-dangerous shots coming from a given region of the ice than average, and blue regions show fewer-and-less-dangerous shot patterns than average. White regions see shot patterns that are roughly as dangerous as average. A full explanation of this expected goals model can be found here and the cleverness required to encode xG rates in pictures here.
For convenience, the xG rate of the term, relative to baseline 5v5 xG rate, is also shown in the neutral zone. So, displayed above, the effect on shots to being the home team in the second period +13.6% xG/60, which means that simply being the home team (in addition to any benefit gained by matchups) is associated with generating a pattern of shots likely to result in 13.6% more goals per hour than league average, given average shooting and goaltending talent.
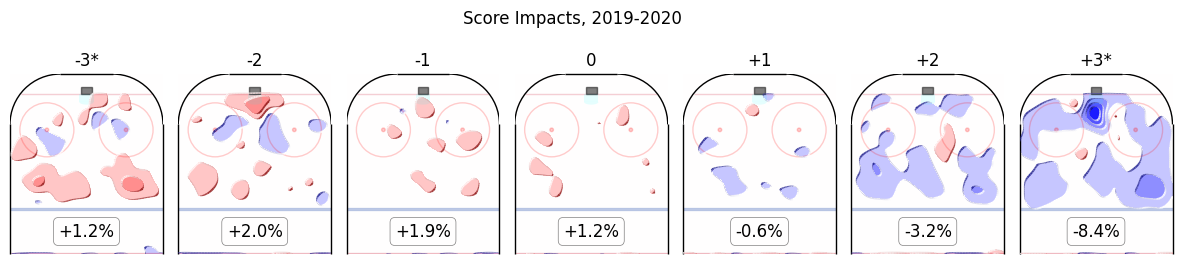
Score
The six score terms are as follows:
Fatigue
The eight fatigue terms are as follows:
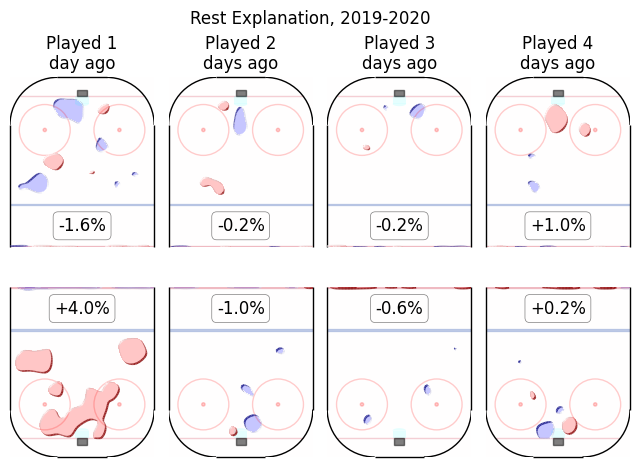
These terms are additive, so a given player might have played last night and also three days ago, so the impact of fatigue on that player can be obtained by adding both of those maps. Predictably, the effects of fatigue are negative, and the strongest effect is from having played the previous night. The other terms seem by comparison very unimportant and in the future I might well delete them.
Zone
The three zone terms are as follows:

The pooling penalties permit us to compare all of the zone starts to one another directly. As expected, starting in the offensive zone helps boost shot rates considerably, and starting in your own zone depresses your shot rates even more. Perhaps surprisingly, starting a shift in the neutral zone depresses shot rates nearly as much; the blue lines (or, more to the point, the offside rules) are formidable obstacles. The on-the-fly term being positive is evidence that the feeling of games with fewer whistles being more exciting is not an illusion caused by total running time being shorter; such games really do have more and more dangerous 5v5 shots.
Distributions
One obvious reason to construct such a model is to suss out the abilities of players, which is intrinsically interesting. However, we can also make comparisons about how much each of the various factors in our models affect play.
"Raw" on-ice results
Before I describe the model outputs, I turn first to the raw observed results from the 2019-2020 regular season.

This graph is constructed as follows: for every skater who played any 5v5 minutes, compute the xG created and allowed by their team while they were on the ice; this produces a point \((x,y)\). Then, form the density map of all such points, where each point is weighted by the corresponding number of minutes played by the player in question. For ease of interpretation, I've scaled the xG values by league average, so that a value of \((5,5)\) on the graph means "threating to score 5% more than league average, and also threatening to be scored on 5% more than league average". As is my entrenched habit, the defensive axis is inverted, so results that are favourable to the skater in question appear in the top right (marked "GOOD" so that there can be no doubt). The contours are chosen so that ten percent of the point mass is in the darkest region, another ten percent in the next region, and so on. The final ten percent of the point mass is in the white region surrounding the shaded part of the graph. For convenience the weighted sum of the values (the centre of mass of the distribution, if it were a mountain you could balance on the tip of your finger) is marked with a red dot.
Player Marginals
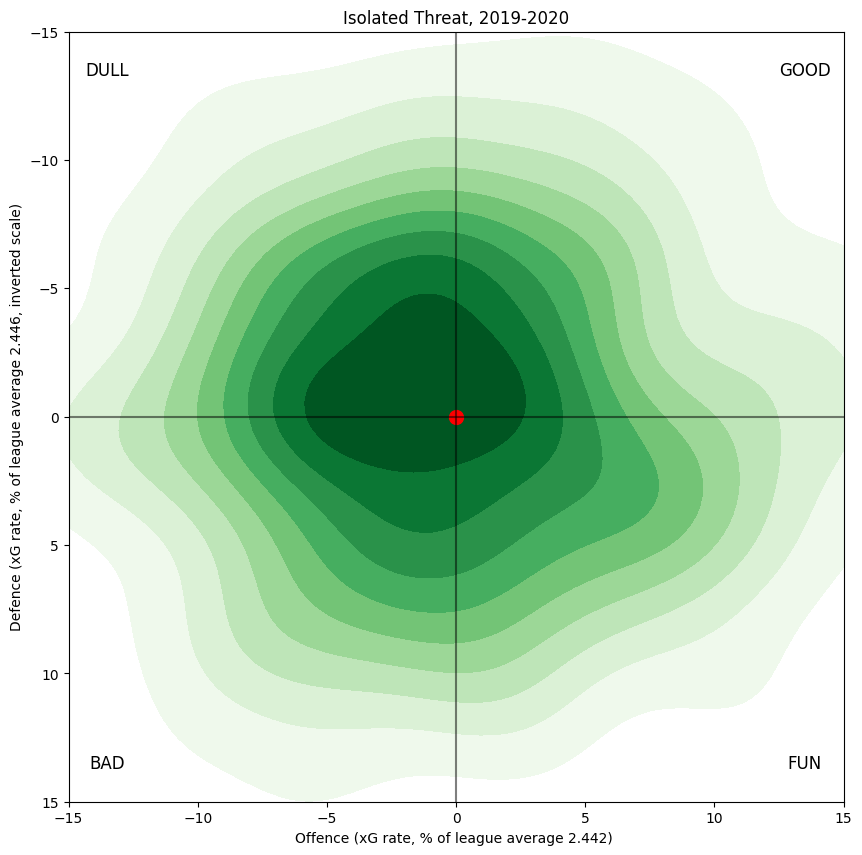
Repeating the above process with the individual player marginal estimates gives the following graph in green. The overall shape is still broadly normal, for clarity I've subtracted out the (tiny) difference between the regression baseline (a map with an xG/60 of 2.442) and the centre-of-mass of the distribution, with coordinates (-0.010%, -0.17%). Although this produces a mean-centred distribution it still has some interesting structure; in particular the mode (what would correspond to the "summit" of the mountain of data) is shifted perceptibly towards "dull". The players with abilities in the other quadrants are less common but play more minutes, on average, especially "fun" players who generate a lot of offence but also concede a lot. Roughly, to my eye, these "fun" players are usually marquee names, frequently great shooters talents also, for whom such a play-style is wise; the more common players huddle with their meagre minutes towards "dull".
One guiding principle of mine is that I don't include any terms in the model itself that identify players by position, since I would like to be able to measure differences between positions. With that in mind, here is the same density as above, but only for forwards:
Forwards
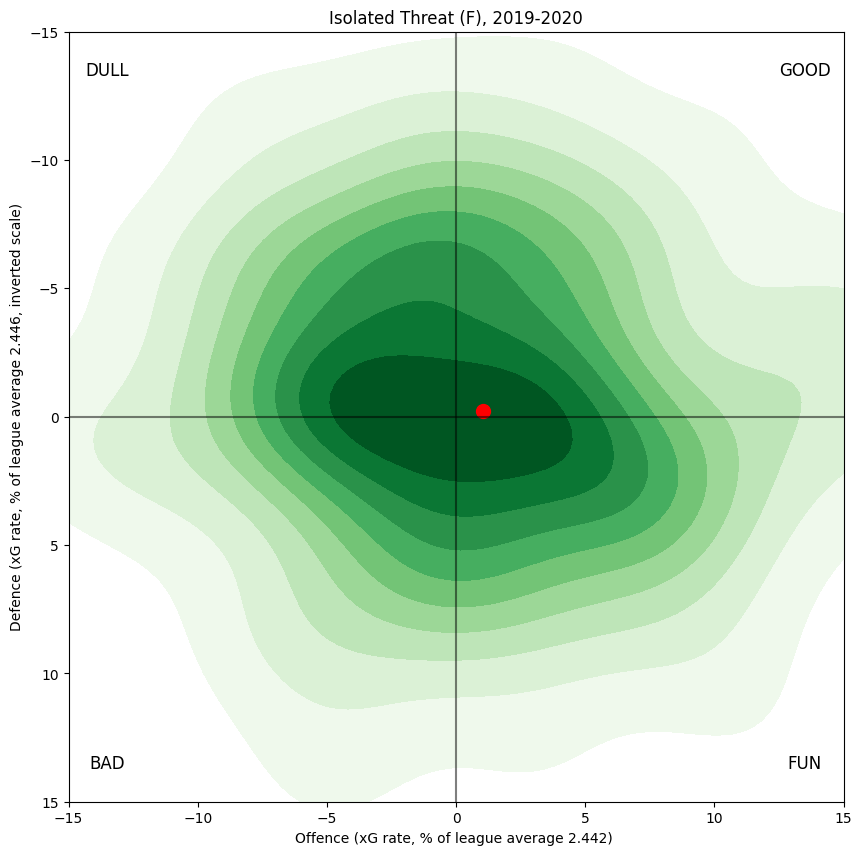
Defenders
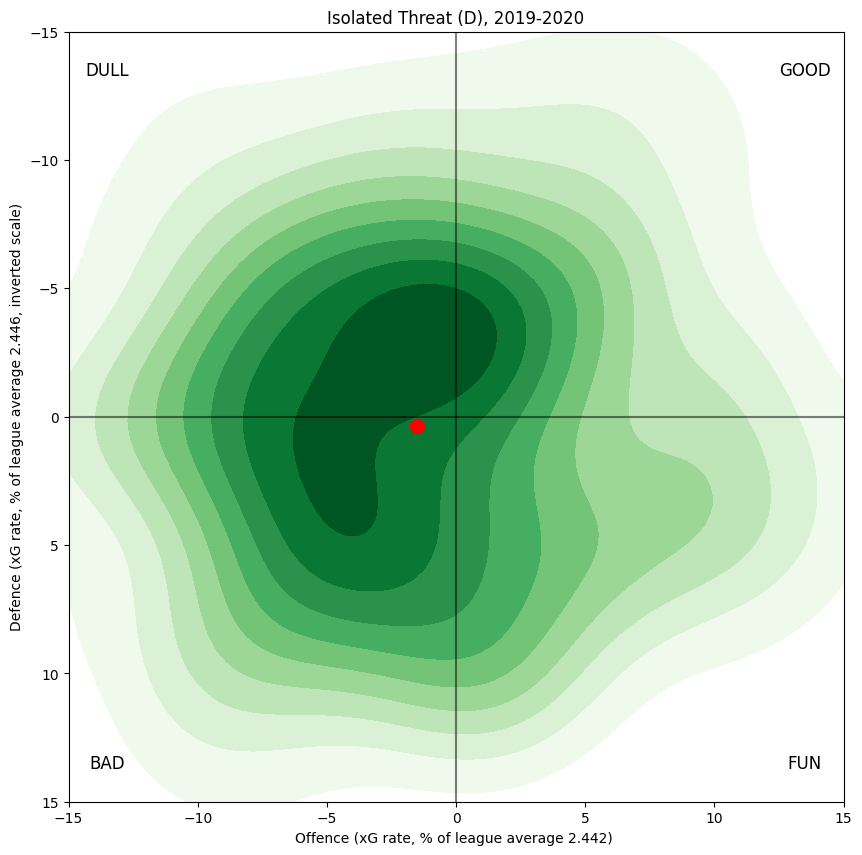
Not surprisingly, forwards generate somewhat more offence, on average. The difference between the centre-of-masses of the two distributions is a little less than two per cent of league average xG per hour.
Teammate Impact
Once I have individual estimates for players in hand, I can make many interesting secondary computations to show the distribution of various effects. Most obviously, for a given player, I can form the sum of the player estimates of all the given player's teammates, weighted by their shared icetime, and then multiply it by four (since every player has four teammates at 5v5). These estimates of teammate quality can then be graphed as above:
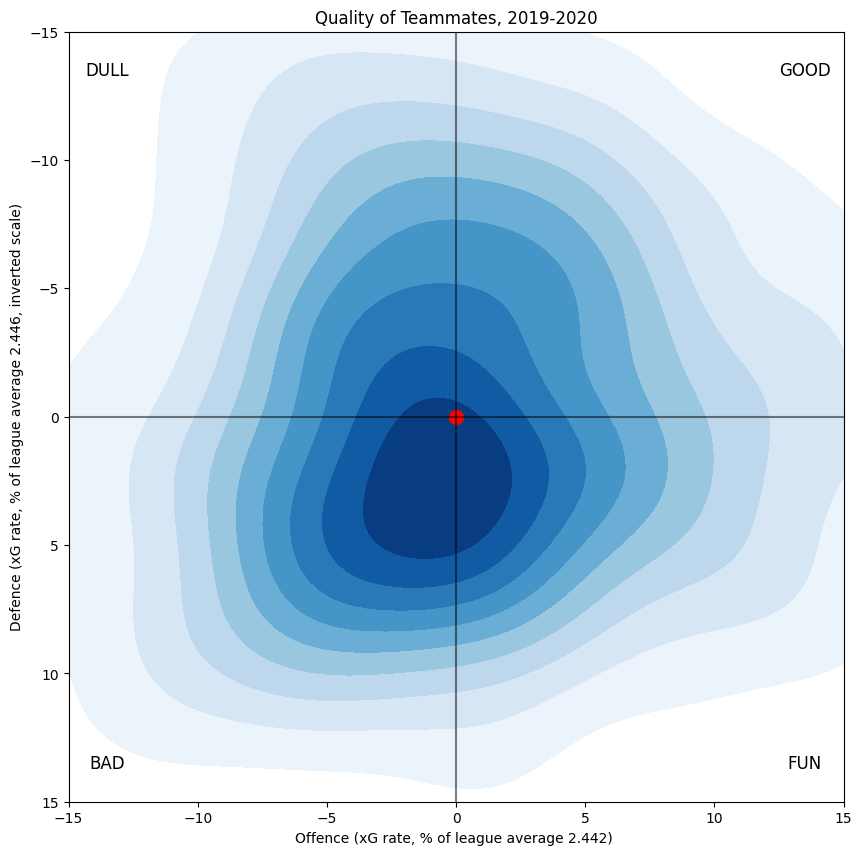
Since I centred the plot of the player ability distribution, this one is also centred.
Opponent Impact
The same computation can be done for any given players 5v5 opponents: form the sum of all of their isolates, weighted by head-to-head icetime, and then multiply by five, since every player has five opponents at 5v5. This is graphed below in red:

First, notice that the scale on the axes is smaller than for teammates; more discussion of that will follow later. The variation in competition quality is more pronounced offensively, with the range of defensive ability faced by players is much smaller.
If we add together the effect of each player's teammates and the effect of their competition, we obtain a distribution that is roughly normal around zero, as expected.
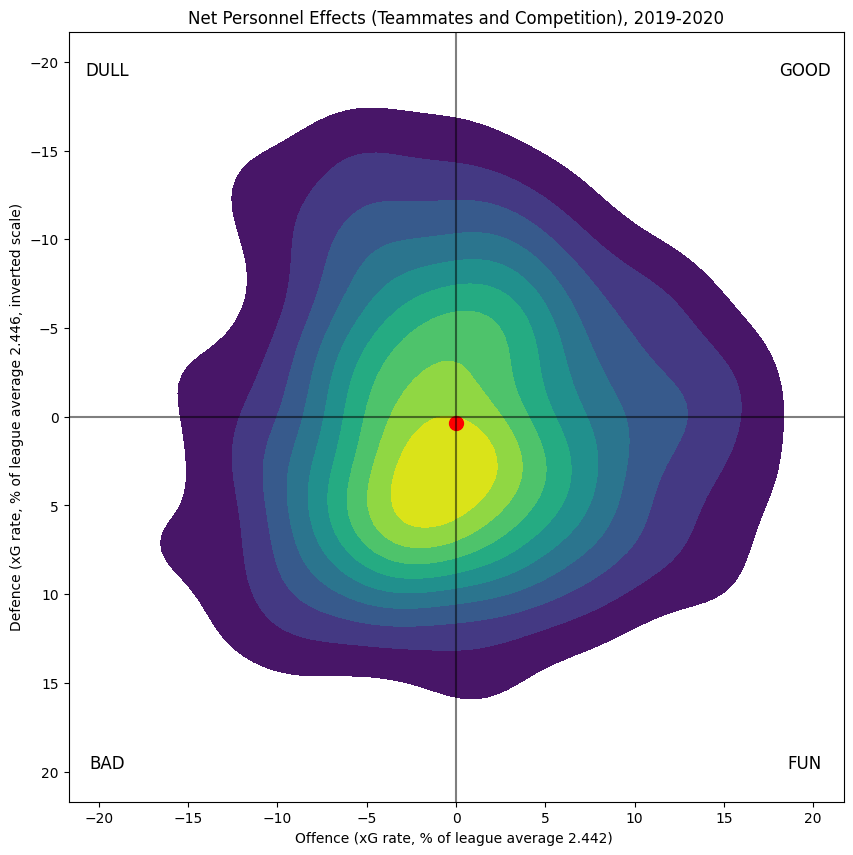
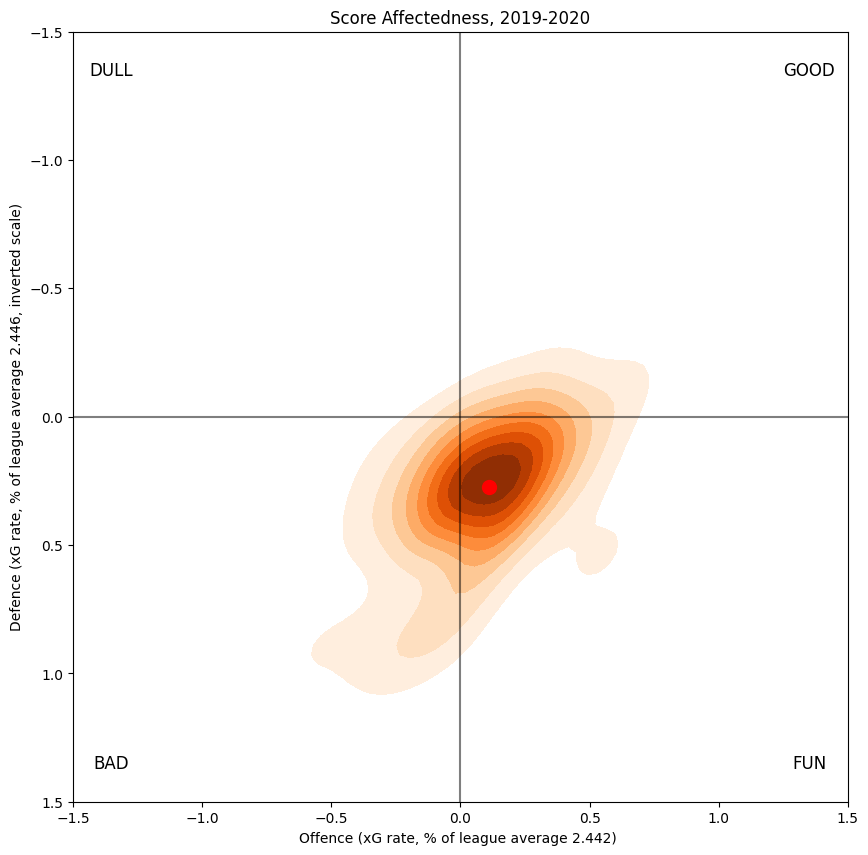
Score Impact
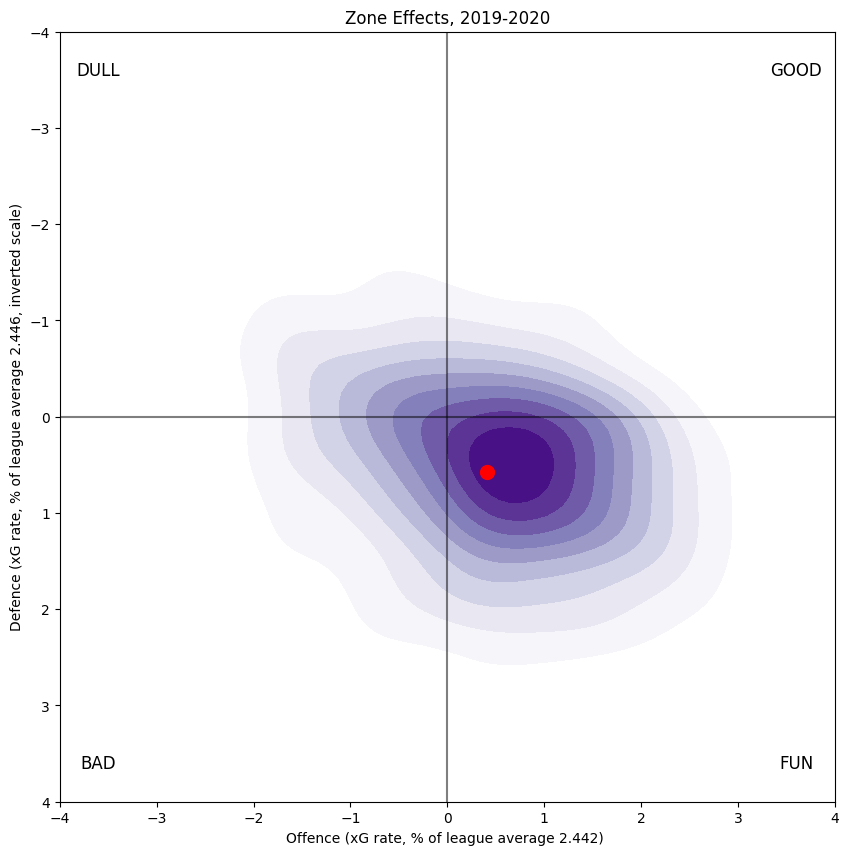
Zone Impact
Coach Impact
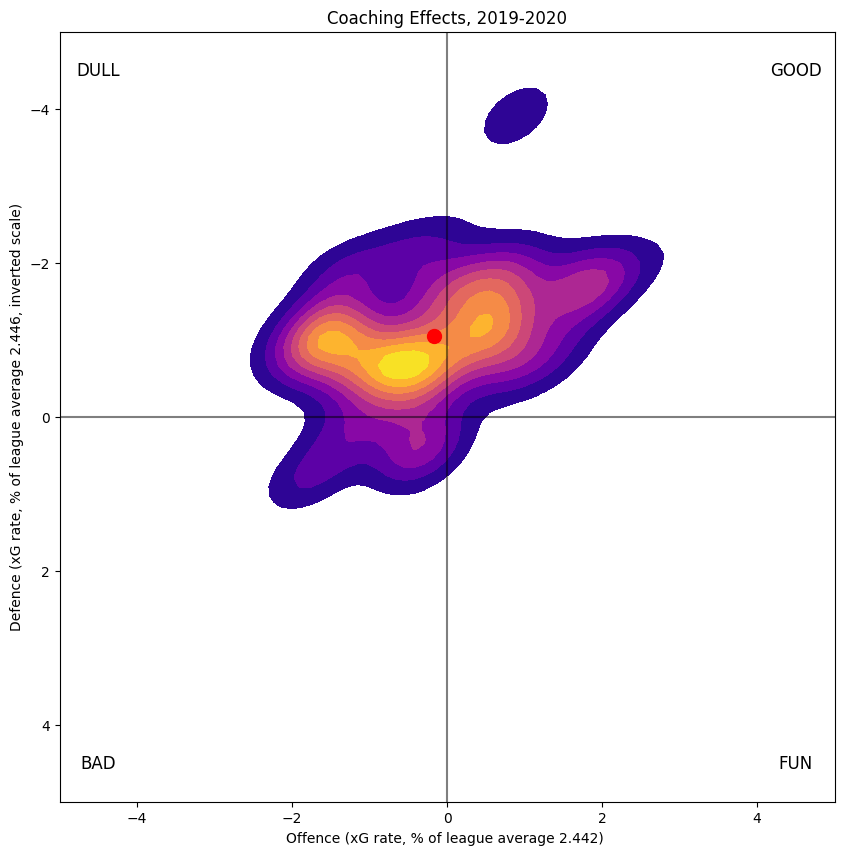
Since coaches change and players change teams, not every player is affected by head coaching the same amount. That said, there are only around thirty-five or forty head coaches in the league each year, so the distribution of coaching effects on players is lumpier. (The blob near the GOOD/DULL border is players who played most of their minutes under Ralph Krueger, who has presided over considerable improvement in the Sabres defence).
The above shows the impact on players due to coaches, both the general terms and the shell terms, as appropriate. To see the coach terms specifically, I've condensed them here:
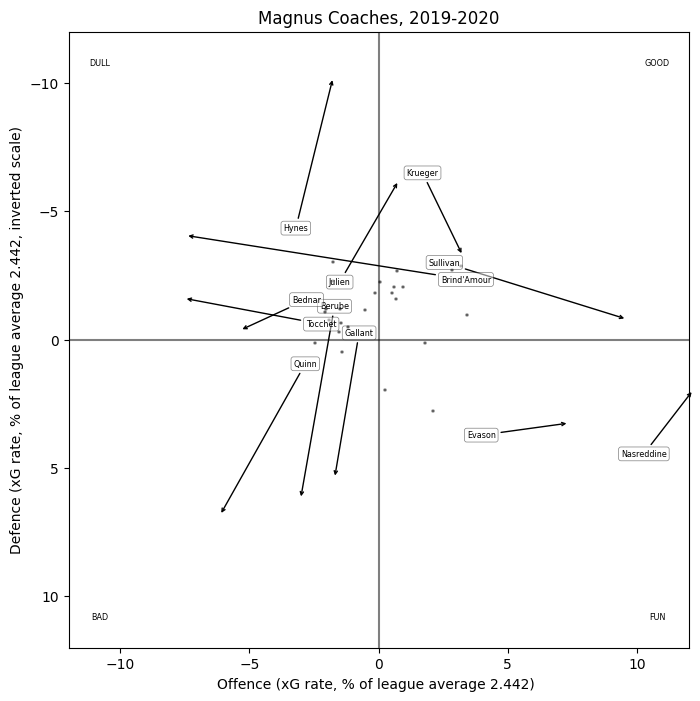
The name shows the "general" terms; the arrows point to the sum of the general terms and the shell terms. David Quinn, for instance, causes his team to generate less offence and concede slightly more than they otherwise might, when in "shell" position this effect is greatly magnified.
The centre of the plot is very crowded and hard to read, so I've also made a zoomed version:
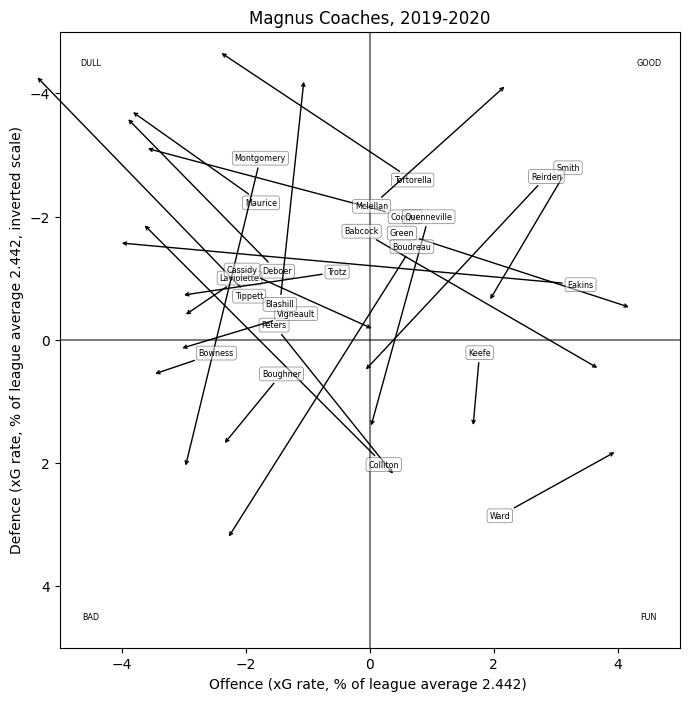
"Residuals"
Strictly speaking, residuals for a regression refer to the differences between the individual observations (that is, each stint) and the predicted shot rates for that stint. As a perhaps more insightful alternative, for each player, I can compute the difference between their raw (observed) 5v5 on-ice results and what I would expect from computing the model outputs associated with the observed players and the zones and scores and home-ice advantage they player under. This is shown below:
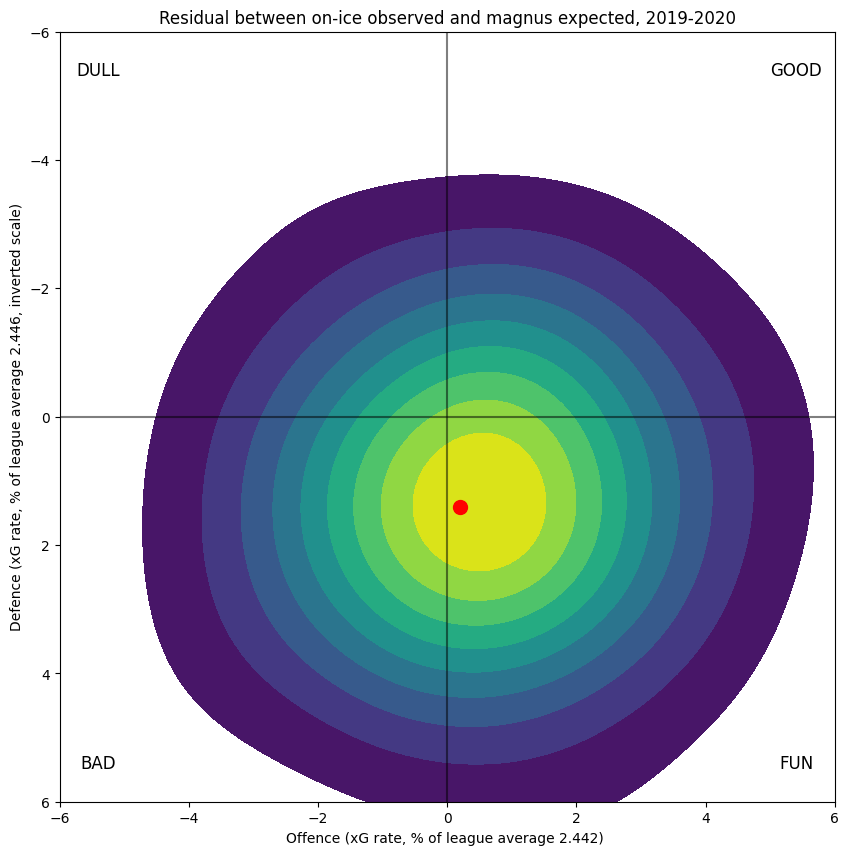
This makes a sort of "goodness of fit" measure. The obviously circular shape is encouraging; the skew towards "fun" suggests that there are, in aggregate, more shots than can be reliably attributed to any particular source that I've modelled here. Perhaps there is some right-skewed random process lurking in the sport, or perhaps the "good"/"fun" players are being biased back towards zero too much. I remain unsure.
Relative Scale
In the above, I have shown each distribution on its own scale, so that I could discuss the shape of each one in turn. However, to understand their relative importance, they should all be placed on the same scale, which I have done below (except the residuals):

Here there are many interesting insights to be had:
- The teammate distribution is much bigger than the competition distribution, in agreement with many previous studies showing that variation in competition (which is only loosely controlled by coaches) is much smaller than the variation in teammates, which coaches control almost completely. However, there are certain players for whom the net impact of competition is much larger than that of teammates, even over the scale of full seasons. In general, a careful analysis should always begin with teammates but also include competition and contextual effects.
- Controlling for teammates, competition, and zone effects, as we do, the aggregate size of score effects is surprisingly small—almost negligible. Within a single game the score is important; at the scale of a whole season it is not, for most players.
- Zone effects are also surprisingly small; their total extent is considerably smaller than competition effects which are themselves smaller than teammate effects. By focussing on only offensive zone faceoffs and defensive zone faceoffs, as some analyses do, differences between contexts which are in fact quite small can appear heavily inflated.
- Coaching effects, over and above coaching choices like score and zone usage, have a non-trivial effect but still pale in comparison to teammates and competition.
- The fatigue distribution is incredibly tiny, invisible in comparison to the others. (In fact it is so small it can't be seen on axes at this scale, so I didn't graph it)
Previous Work and Acknowledgements
Using zero-biased (also known as "regularized") regression in sports has a long history; the first application to hockey that I know of is the work of Brian MacDonald in 2012. His paper notes many earlier applications in basketball, for those who are curious about history; also I am very grateful for many useful conversations with Brian during the preparation of the first version of Magnus. Shortly after MacDonald's article followed a somewhat more ambitious effort from Michael Schuckers and James Curro, using a similar approach. Persons interested in the older history of such models will be delighted to read the extensive references in both of those papers.
More recently, regularized regression has been the foundation of WAR stats from both Emmanuel Perry and Josh and Luke Younggren, who publish their results at Corsica and Evolving-Hockey, respectively.
Finally, I am very thankful to Luke Peristy for many helpful discussions, and to the generalized ridge regression lecture notes of Wessel N. van Wieringen which were both of immense value to me.
As far as I can tell, the extension of ridge regression to functions (that is, shot maps instead of just single numbers) is new, at least in this context.
Player and Coach Results
While my research has always been free to the public and will remain so, I restrict access to the specific regression outputs for players and coaches to website subscribers. To gain access, please subscribe at the $5 tier (or higher, of course); then after logging in you should be able to find coaching terms, and individual player terms are on the career pages for each player.